Table of Contents Introduction The Transformer is currently one of the most popular architectures for NLP. We can periodically hear news about new architectures and models based on transformers generating a lot of buzz and expectations in the community. Google Research and members from Google Brain initially proposed the Transformer...
Continue reading...Machine Learning
Support Vector Machines (SVM) for Classification
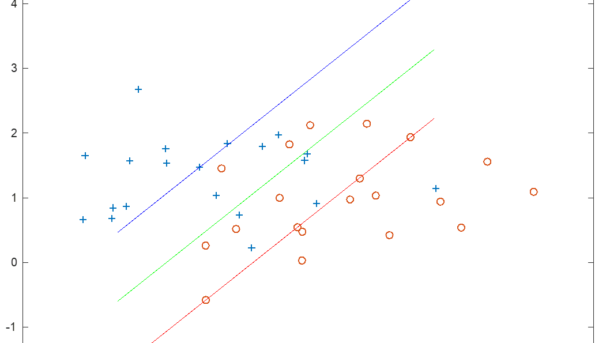
The purpose of this document is to present the linear classification algorithm SVM. The development of this concept has been based on previous ideas that have supported the development of SVM as an algorithm with good generalization capacity, based on an optimization criterion that minimizes complexity; with which we have...
Continue reading...TensorFlow High-Level Libraries: TF Estimator
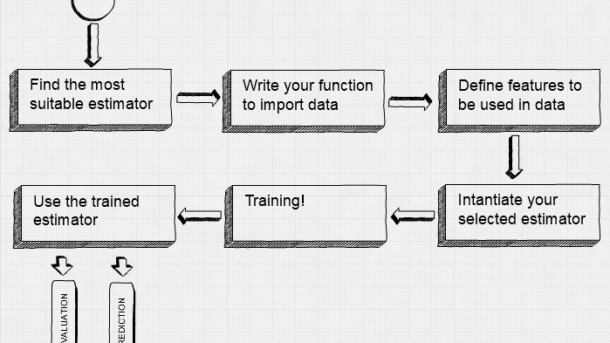
TensorFlow has several high-level libraries allowing us to reduce time modeling all with core code. TF Estimator makes it simple to create and train models for training, evaluating, predicting and exporting. TF Estimator provides 4 main functions on any kind of estimator: estimator.fit() estimator.evaluate() estimator.predict() estimator.export() All predefined estimators are...
Continue reading...TensorFlow Way for Linear Regression
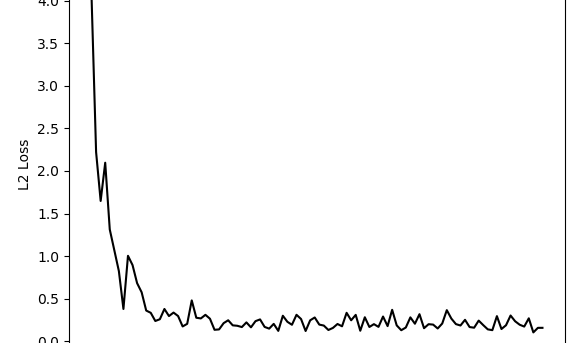
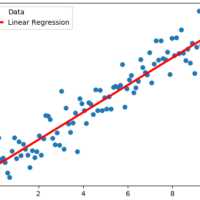
In my two previous posts, we saw how we can perform Linear Regression using TensorFlow, but I’ve used Linear Least Squares Regression and Cholesky Decomposition, both them use matrices to resolve regression, and TensorFlow isn’t a requisite for this, but you can use more general packages like NumPy. One of...
Continue reading...Cholesky Decomposition for Linear Regression with TensorFlow

Several years have already passed since the onset of the Deep Learning boom. I have witnessed impressive achievements like ChatGPT and Midjourney, however, I am still amazed at how traditional methods like Cholesky decomposition remain extremely useful and efficient. Particularly, for tasks like Linear Regression, this method stands out due...
Continue reading...Linear Least Squares Regression with TensorFlow
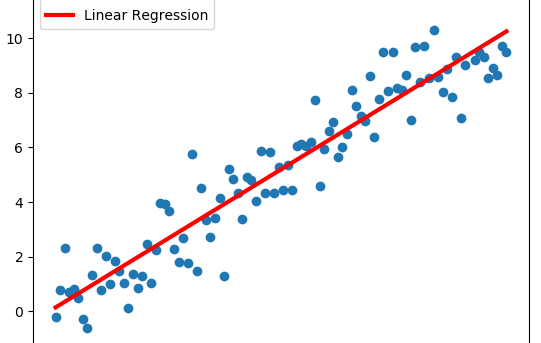
Linear Least Squares Regression is by far the most widely used regression method, and it is suitable for most cases when data behavior is linear. By definition, a line is defined by the following equation: For all data points (xi, yi) we have to minimize the sum of the squared...
Continue reading...Classification Loss Functions (Part II)
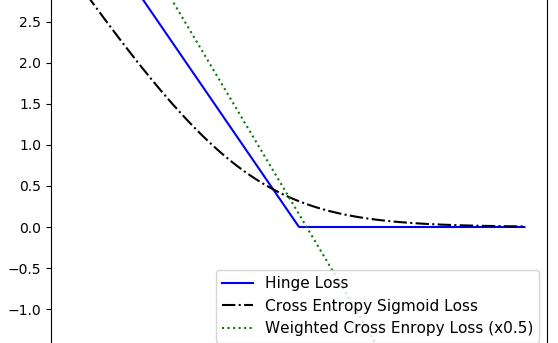
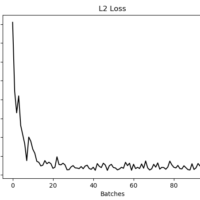
In my previous post, I mentioned 3 loss functions, which are mostly intended to be used in Regression models. This time, I’m going to talk about Classification Loss Functions, which are going to be used to evaluate loss when predicting categorical outcomes. Let’s consider the following vector to help us...
Continue reading...Loss Functions (Part 1)
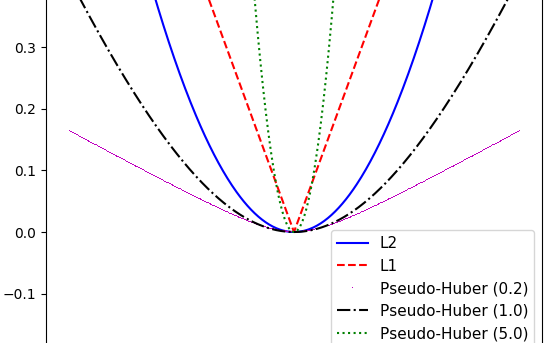
Implementing Loss Functions is very important to machine learning algorithms because we can measure the error from the predicted outputs to the target values. Algorithms get optimized by evaluating outcomes depending on a specified loss function, and TensorFlow works in this way as well. We can think on Loss Functions...
Continue reading...Activation Functions (updated)
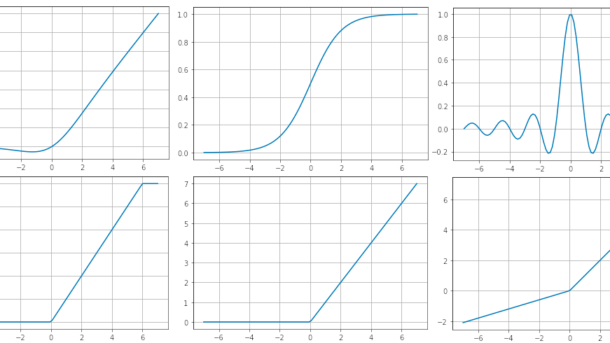
Table of Contents What is an activation function? Activation Functions Sigmoid ReLU (Rectified Linear Unit) ReLU6 Hyperbolic Tangent ELU (Exponential Linear Unit) Softmax Softplus Softsign Swish Sinc Leaky ReLU Mish GELU (Gaussian Error Linear Unit) SELU (Scaled Exponential Linear Unit) What is an activation function? An activation function is a...
Continue reading...Working with Matrices in TensorFlow
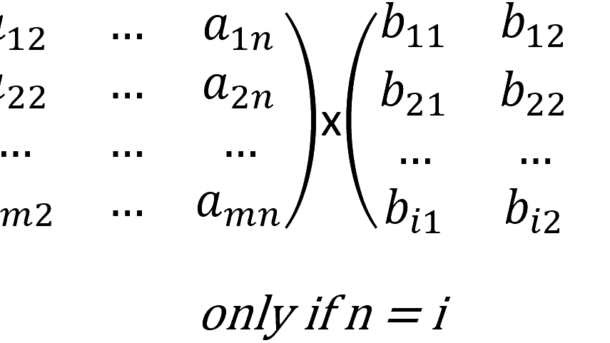
Matrices are the basic elements we use to interchange data through computational graphs. In general terms, a tensor can de defined as a matrix, so you can refer to Declaring tensors in TensorFlow in order to see the options you have to create matrices. Let’s define the matrices we are...
Continue reading...