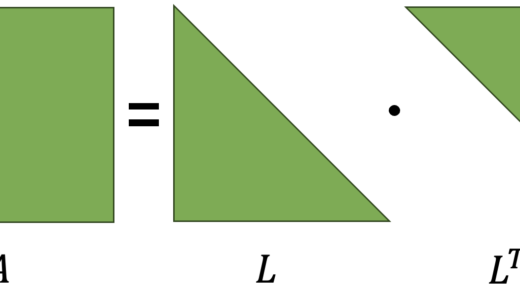Implementing Loss Functions is very important to machine learning algorithms because we can measure the error from the predicted outputs to the target values. Algorithms get optimized by evaluating outcomes depending on a specified loss function, and TensorFlow works in this way as well. We can think on Loss Functions telling us how good the predictions are compared to the expected values.
There are several loss functions we can use to train a machine learning algorithm, and I’ll try to explain some of them and when we can use them. Let’s consider the following vector to help us to show how loss functions behave:
import tensorflow as tf
sess = tf.Session()
# f(x) and target = 0
x_function = tf.linspace(-1., 1., 500)
target = tf.constant(0.)L2-norm Loss Function (Least Squares Error LSE)
It is just the sum of the square of the distance to the target

L2 squares the error increasing by a lot if error > 1 (outlier can cause this kind of error), so the model is very sensitive to variations, and, when it is used to optimize an algorithm, it adjusts the model to minimize the error.
For any small adjustments of a data point, the regression line will move only slightly (regression parameters are continuous functions of the data).
TensorFlow has a built-in implementation, called tf.nn.l2_loss(), which actually perform the half of the previous equation.

In order to show you how loss functions behave, we are going to plot the points before to perform the summatory.
L2_function = tf.square(target - x_function)
L2_output = sess.run(L2_function)L1-norm Loss Function (Least Absolute Error LAE)
It is just the sum of the absolute value of the distance to the target

If we compare L1 with L2, we can deduct that L1 is less sensitive to errors caused by outliers (because it doesn’t square the error). So, if we need to ignore the effects of outliers, we could consider using L1 instead of L2, if it is important to consider outliers, then L2 is a better option.
One issue to be aware of is that the L1 is not smooth at the target and this can result in algorithms not converging well.
L1_function = tf.abs(target - x_function)
L1_output = sess.run(L1_function)Pseudo-Huber Loss Function
It is a smooth approximation to the Huber loss function. Huber loss is, as Wikipedia defines it, “a loss function used in robust regression, that is less sensitive to outliers in data than the squared error loss [LSE]”. This loss function attempts to take the best of the L1 and L2 by being convex near the target and less steep for extreme values. The form depends on an extra parameter, delta, which dictates how steep it will be.

We are going to test 3 values for delta:
delta1 = tf.constant(0.2)
pseudo_huber1 = tf.multiply(tf.square(delta1), tf.sqrt(1. + tf.square((target - x_function)/delta1)) - 1.)
pseudo_huber1_output = sess.run(pseudo_huber1)
delta2 = tf.constant(1.)
pseudo_huber2 = tf.multiply(tf.square(delta2), tf.sqrt(1. + tf.square((target - x_function) / delta2)) - 1.)
pseudo_huber2_output = sess.run(pseudo_huber2)
delta3 = tf.constant(5.)
pseudo_huber3 = tf.multiply(tf.square(delta3), tf.sqrt(1. + tf.square((target - x_function) / delta2)) - 1.)
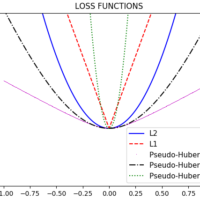
pseudo_huber3_output = sess.run(pseudo_huber3)Let’s plot this loss functions!
import matplotlib.pyplot as plt
x_array = sess.run(x_function)
plt.plot(x_array, L2_output, 'b-', label='L2')
plt.plot(x_array, L1_output, 'r--', label='L1')
plt.plot(x_array, pseudo_huber1_output, 'm,', label='Pseudo-Huber (0.2)')
plt.plot(x_array, pseudo_huber2_output, 'k-.', label='Pseudo-Huber (1.0)')
plt.plot(x_array, pseudo_huber3_output, 'g:', label='Pseudo-Huber (5.0)')
plt.ylim(-0.2, 0.4)
plt.legend(loc='lower right', prop={'size': 11})
plt.title('LOSS FUNCTIONS')
plt.show()
Conclusions
I have several outliers but they are not so important, which loss function should I use?
L1 Loss Function, but probably you will have problem to converge to the best solution, so consider low learning rate.
I have several outliers, they occur under circumstances that I should take in account. Which loss function should I use?
L2 Loss Function, but too separated outlier could affect the model so probably you could consider normalize data before
I have several outliers, I don’t want them to affect my model and I need to converge to the best solution.
Use Pseudo-Hubber Loss Function, you need to take care of DELTA, a too big value as 5.0 could make the outliers affect your model again, and a too small value as 0.1 could make your model very slow to converge to solution.